
Data engineering has become integral to working with big data. This is largely because the field of big data is progressing rapidly, and new technologies are continuously needed to deal with it.
RELATED ARTICLE: HOW TO BECOME A BUSINESS ANALYTICS EXPERT
The world of information technology is rapidly evolving. Just look at the huge volumes of data businesses rely on. But strangely enough, big data require a certain structuring in order for anyone to work comfortably with it. This is why data engineering exists.
In fact, this field has become integral to working with big data. As proof, look at the explosive development of big data in USA. New technologies are constantly in demand to make it easier for people to manage it.
It has become clear to most that well-functioning, effective management systems lead to success. Therefore, it is immediately clear why data engineering plays a huge role in big data strategy. In this article, we look at what data engineering is. We discuss its impact and importance and take a look at an example of a data pipeline.
What Is Data Engineering?
The essence of data engineering is the designing and building of systems that collect and analyze raw data from a variety of sources and formats. Data scientists and business analysts are then better able to interpret the data. In this way, businesses can use data to evaluate and optimize their operations.
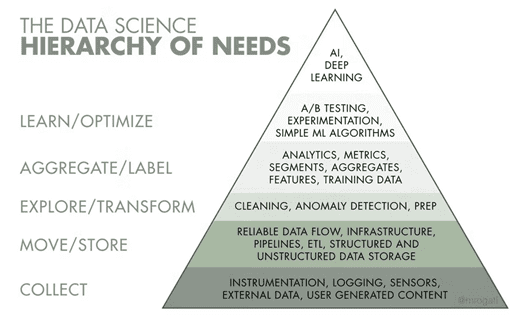
If we look at the pyramid above, which shows the needs of data science, we immediately notice that data engineering occupies the base. This means that the collecting, storing, moving, and transforming of data is foundational to the entire pyramid. In other words, you could say that it’s up to the data engineers to make everything else possible. In other words, without data engineering at the base of the pyramid, there would be no apex, or no deep AI learning.
RELATED ARTICLE: IOT AND BIG DATA ARE SHAPING THE FUTURE OF MARKETING
The field of data engineering provides the designing, processing, creating, and maintaining of all the data. This is essential for the efficient storage of data. Since the data itself comes from many sources, it must be seamlessly processed and stored so that analysts and scientists can access it conveniently.
Why Is Data Engineering So Important?
What advantages does data engineering provide? What does it give us in the end?
First of all, this field optimizes data for multiple uses. Many businesses require data analytics systems that meet strict requirements. For example, businesses related to e-commerce require data analytics that lead to greater productivity and more sensitive fault tolerance.
In addition, data engineering plays an important role in the fields of information security, data fusion, machine learning, and data generation for automation.
Over time, technological innovations have had a huge effect on data viability. These innovations include cloud technologies and open source projects in particular.
Moreover, the sheer volume of data today highlights the importance of engineering skills when it comes to organizing large amounts of data. The organizational structure must be not only complete, but also consistent. This is the challenge data engineers face.
What Are Data Pipelines?
Most of the time, the data engineer builds what is called a pipelining dataset. That is, the engineer creates a process for delivering data from one place to another. These can be custom scripts. Some might go to an external service API. Others could make an SQL query. Then, the script augments the data and puts it into a centralized repository or unstructured data repository.
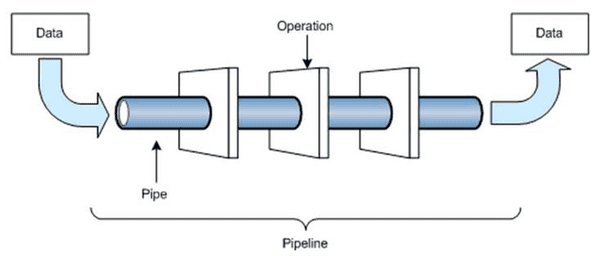
The data processing pipeline then takes the input data through a set of operations that transform it. Because the information always arrives at the input point of the pipeline in an untested and unstructured form, these operations are truly complex. However, consumers want to see their data in an easy-to-understand form. Therefore, data processing pipelines are one of the most in-demand items in the big data industry.
Let’s Sum It Up
Data engineering is a critical part of any task that involves large flows of information. This is because raw data requires structuring and transformation so that consumers can understand it easily. Therefore, it’s safe to say that as the volume of information grows, the need for data engineering will increase accordingly.
RELATED ARTICLE: STRATEGIC THINKING IN THE DIGITAL AGE